The latest Amazon AWS Certified Specialty exam dumps update

The Amazon AWS Certified Specialty certification includes many:
- ANS-C00 – AWS Certified Advanced Networking – Specialty (ANS-C00)
- AXS-C01 – AWS Certified Alexa Skill Builder – Specialty (AXS-C01)
- BDS-C00 – AWS Certified Big Data – Speciality (BDS-C00)
- DAS-C01 – AWS Certified Data Analytics – Specialty (DAS-C01)
- DBS-C01 – AWS Certified Database – Specialty (DBS-C01)
- MLS-C01 – AWS Certified Machine Learning – Specialty (MLS-C01)
- SCS-C01 – AWS Certified Security – Specialty (SCS-C01)
How to pass any exam in AWS Certified Specialty?
The study, exam practice, discussion group, previous exam questions, can help you improve your exam skills! 100% exam guarantee is dumped in Amazon AWS Certified Specialty advanced exam, you can check geekcert
Get any certification dumps on the Amazon AWS Certified Specialty page to help you successfully pass the exam.
How about the geekcert IT certification dumps learning method?
All certification exam dumps contain two modes: PDF and VCE. Either mode can help you easily learn to pass the exam.
Does geekcert have an exam guarantee?
Of course. geekcert guarantees your first exam success, you can go to the Lead4Pas homepage to view the full policy.
Participate in the Amazon AWS Certified Specialty exam practice for more advanced exam questions and free PDFs
ANS-C00 – AWS Certified Advanced Networking – Specialty
QUESTION 1
When using AWS Config, which two items are stored on S3 as a part of its operation?
A. Configuration Items and Configuration History
B. Configuration Recorder and Configuration Snapshots
C. Configuration History and Configuration Snapshots
D. Configuration Snapshots and Configuration Streams
Correct Answer: C
Explanation: S3 is used to store the Configuration History files and any Configuration Snapshots of your data within a single bucket, which is defined within the Configuration Recorder. You can get AWS Config to create a new bucket for you and select an existing bucket. If you have multiple AWS accounts you may want to aggregate your Configuration History and Snapshot files into the same S3 Bucket for your primary account, just be aware that this can be achieved.
However, you will need to grant write access for the service principal (config.amazonaws.com) in your other accounts write access to the S3 bucket.
Reference: http://docs.aws.amazon.com/config/latest/developerguide/config-concepts.html#config-items
QUESTION 2
The Security department has mandated that all outbound traffic from a VPC toward an on-premises datacenter must go through a security appliance that runs on an Amazon EC2 instance.
Which of the following maximizes network performance on AWS? (Choose two.)
A. Support for the enhanced networking drivers
B. Support for sending traffic over the Direct Connect connection
C. The instance sizes and families supported by the security appliance
D. Support for placement groups within the VPC
E. Security appliance support for multiple elastic network interfaces
Correct Answer: BC
QUESTION 3
You currently use a single security group assigned to all nodes in a clustered NoSQL database. Only your cluster
members in one region must be able to connect to each other. This security group uses a self-referencing rule using the cluster security group\\’s group-id to make it easier to add or remove nodes from the cluster. You need to make this database comply with out-of-region disaster recovery requirements and ensure that the network traffic between the nodes is encrypted when travelling between regions. How should you enable secure cluster communication while deploying additional cluster members in another AWS region?
A. Create an IPsec VPN between AWS regions, use private IP addresses to route traffic, and create cluster security group rules that reference each other\\’s security group-id in each region.
B. Create an IPsec VPN between AWS regions, use private IP addresses to route traffic, and create cluster security
group CIDR-based rules that correspond with the VPC CIDR in the other region.
C. Use public IP addresses and TLS to securely communicate between cluster nodes in each AWS region, and create cluster security group CIDR-based rules that correspond with the VPC CIDR in the other region.
D. Use public IP addresses and TLS to securely communicate between cluster nodes in each AWS region, and create cluster security group rules that reference each other\\’s security group-id in each region.
Correct Answer: D
QUESTION 4
What is the IPv6 subnet CIDR used by a VPC?
A. /128
B. /56
C. /48
D. /16
Correct Answer: B
Explanation:
A VPC will always use /56 as its CIDR
QUESTION 5
Your company has just completed a transition to IPv6 and has deployed a website on a server. You were able to
download software on the instance without an issue. This website is deployed using IPv6, but the public is not able to access it. What should you do to fix this problem?
A. Add an internet gateway for the instance.
B. Add an egress-only internet gateway.
C. Add an inbound rule to your security group that allows inbound traffic on port 80 for ::/0.
D. Add an inbound rule to your security group that allows inbound traffic on port 80 for 0.0.0.0/0.
Correct Answer: C
Explanation:
Your instance can reach the internet if it was able to download sofftware, so an IGW is not needed.
0.0.0.0/0 is for IPv4.
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/112s5evlY3wmjJrxBw0CssxoQ-1Rt66yB/view?usp=sharing
Advanced Amazon ANS-C00 Dumps
geekcert ANS-C00 dumps: https://www.geekcert.com/aws-certified-advanced-networking-specialty.html (Total Questions: 377 Q&A)
AXS-C01 – AWS Certified Alexa Skill Builder – Specialty
QUESTION 1
An Amazon Alexa skill fetches data for users from a third-party API and the wait for the response from that call is
variable, often taking up to 5 seconds. What is the recommended method for notifying users that a skill is working on the request and has not failed to respond?
A. Prefetch the data that is expected to the required by the skill from the third-party API using Amazon CloudWatch Events.
B. Call the Progressive Response API and send a directive, such as VoicePlayer.Speak
C. Ask a follow-up question for clarification to engage the user while waiting for the initially requested response.
D. Respond to the user stating that the data will be ready soon, and upon the next launch of the skill, provide the user with the response they initially requested.
Correct Answer: B
Reference: https://developer.amazon.com/en-US/docs/alexa/custom-skills/send-the-user-a-progressive-response.html
QUESTION 2
An Alexa Skill Builder wants to customize a welcome back message for each person who uses the skill. The JSON input is shown below: Which element from the request would the Builder use to accomplish this?

A. sessionId
B. userId
C. requestId
D. applicationId
Correct Answer: A
QUESTION 3
An Alexa Skill Builder receives feedback from users that a specific utterance causes Amazon Alexa to trigger the skill\\’s AMAZON.HelpIntent rather than triggering the correct intent and slot. How can the Builder reproduce this behavior to troubleshoot the problem?
A. Use the AWS Lambda test feature to send a request with the given intent and slot combination.
B. Set up a unit test in the code base to simulate what happens when the given intent and slot combination are
dispatched within the skill.
C. Use the Manual JSON tab on the Test page of the developer console to see what happens when a request for the given intent and slot combination is sent to the skill
D. Use the Alexa Simulator tab on the Test page of the developer console to test the utterances the users have
reported.
Correct Answer: B
QUESTION 4
An Alexa Skill Builder is developing a custom skill and needs to verify that the correct slot values are being passed into the AWS Lambda function. According to best practices, what is the MOST efficient way to capture this information?
A. Add a logging statement to write the event request to Amazon CloudWatch Logs.
B. Add an API call to write the environment variables to an Amazon S3 bucket when the function is invoked.
C. Add an API call to read the event information from AWS Cloud Trail logs and add a PutObject API call to write to an Amazon S3 bucket.
D. Add a statement to parse the JSON request and save to the local disk for the Lambda function
Correct Answer: D
Reference: https://developer.amazon.com/en-US/docs/alexa/custom-skills/validate-slot-values.html
QUESTION 5
An Alexa Skill Builder has created a taxi hiring skill. The skill needs to find out when the customer wants a taxi, where the customer is traveling from, and where the customer wants to go. The Builder is currently asking each question individually, in the following order:
“Where do you want to take a taxi from” “Where do you want to take a taxi to” “When do you need a taxi”
To ensure the voice interaction is flexible, how should this information be gathered regardless of the order in which the user provides it?
A. Use a single intent and slot. Inspect the incoming slot value and categorize then response, then prompt for the
remaining information.
B. Create an intent for each question and include slots for each piece of information on every intent
C. Create three intents with one slot each. Use Dialog.ElicitSlot to fill the slots.
D. Create a single intent with three slots. Use the Dialog.Delegate directive to fill the slots.
Correct Answer: D
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/1Ph0Ak9D-HiZd6KEPXnurcVqXg3SBMMlm/view?usp=sharing
Advanced Amazon AXS-C01 Dumps
geekcert AXS-C01 dumps: https://www.geekcert.com/aws-certified-alexa-skill-builder-specialty.html (Total Questions: 65 Q&A)
BDS-C00 – AWS Certified Big Data – Speciality
QUESTION 1
How should an Administrator BEST architect a large multi-layer Long Short-Term Memory (LSTM) recurrent neural
network (RNN) running with MXNET on Amazon EC2? (Choose two.)
A. Use data parallelism to partition the workload over multiple devices and balance the workload within the GPUs.
B. Use compute-optimized EC2 instances with an attached elastic GPU.
C. Use general purpose GPU computing instances such as G3 and P3.
D. Use processing parallelism to partition the workload over multiple storage devices and balance the workload within the GPUs.
Correct Answer: AC
QUESTION 2
A data engineer is running a DWH on a 25-node Redshift cluster of a SaaS service. The data engineer needs to build a dashboard that will be used by customers. Five big customers represent 80% of usage, and there is a long tail of dozens of smaller customers. The data engineer has selected the dashboarding tool.
How should the data engineer make sure that the larger customer workloads do NOT interfere with the smaller
customer workloads?
A. Apply query filters based on customer-id that can NOT be changed by the user and apply distribution keys on
customer-id.
B. Place the largest customers into a single user group with a dedicated query queue and place the rest of the
customers into a different query queue.
C. Push aggregations into an RDS for Aurora instance. Connect the dashboard application to Aurora rather than
Redshift for faster queries.
D. Route the largest customers to a dedicated Redshift cluster. Raise the concurrency of the multi-tenant Redshift
cluster to accommodate the remaining customers.
Correct Answer: D
QUESTION 3
A user has deployed an application on his private cloud. The user is using his own monitoring tool. He wants to
configure that whenever there is an error, the monitoring tool should notify him via SMS.
Which of the below mentioned AWS services will help in this scenario?
A. None because the user infrastructure is in the private cloud/
B. AWS SNS
C. AWS SES
D. AWS SMS
Correct Answer: B
QUESTION 4
You are building a mobile app for consumers to post cat pictures online. You will be storing the images in AWS S3. You want to run the system very cheaply and simply. Which one of these options allows you to build a photo sharing application without needing to worry about scaling expensive uploads processes, authentication/authorization and so forth?
A. Build the application out using AWS Cognito and web identity federation to allow users to log in using Facebook or Google Accounts. Once they are logged in, the secret token passed to that user is used to directly access resources on AWS, like AWS S3. (Amazon Cognito is a superset of the functionality provided by web identity federation. Referlink)
B. Use JWT or SAML compliant systems to build authorization policies. Users log in with a username and password, and are given a token they can use indefinitely to make calls against the photo infrastructure.
C. Use AWS API Gateway with a constantly rotating API Key to allow access from the client-side. Construct a custom build of the SDK and include S3 access in it.
D. Create an AWS oAuth Service Domain ad grant public signup and access to the domain. During setup, add at least one major social media site as a trusted Identity Provider for users
Correct Answer: A
QUESTION 5
An advertising organization uses an application to process a stream of events that are received from clients in multiple unstructured formats.
The application does the following:
Transforms the events into a single structured format and streams them to Amazon Kinesis for real-time analysis.
Stores the unstructured raw events from the log files on local hard drivers that are rotated and uploaded to Amazon S3.
The organization wants to extract campaign performance reporting using an existing Amazon redshift cluster.
Which solution will provide the performance data with the LEAST number of operations?
A. Install the Amazon Kinesis Data Firehose agent on the application servers and use it to stream the log files directly to Amazon Redshift.
B. Create an external table in Amazon Redshift and point it to the S3 bucket where the unstructured raw events are stored.
C. Write an AWS Lambda function that triggers every hour to load the new log files already in S3 to Amazon redshift.
D. Connect Amazon Kinesis Data Firehose to the existing Amazon Kinesis stream and use it to stream the event directly to Amazon Redshift.
Correct Answer: B
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/1Ph0Ak9D-HiZd6KEPXnurcVqXg3SBMMlm/view?usp=sharing
Advanced Amazon BDS-C00 Dumps
geekcert BDS-C00 dumps: https://www.geekcert.com/aws-certified-big-data-specialty.html (Total Questions: 264 Q&A)
DAS-C01 – AWS Certified Data Analytics – Specialty
QUESTION 1
A company has a business unit uploading .csv files to an Amazon S3 bucket. The company\\’s data platform team has set up an AWS Glue crawler to do discovery, and create tables and schemas. An AWS Glue job writes processed data from the created tables to an Amazon Redshift database. The AWS Glue job handles column mapping and creating the Amazon Redshift table appropriately. When the AWS Glue job is rerun for any reason in a day, duplicate records are introduced into the Amazon Redshift table.
Which solution will update the Redshift table without duplicates when jobs are rerun?
A. Modify the AWS Glue job to copy the rows into a staging table. Add SQL commands to replace the existing rows in the main table as postactions in the DynamicFrameWriter class.
B. Load the previously inserted data into a MySQL database in the AWS Glue job. Perform an upsert operation in
MySQL, and copy the results to the Amazon Redshift table.
C. Use Apache Spark\\’s DataFrame dropDuplicates() API to eliminate duplicates and then write the data to Amazon Redshift.
D. Use the AWS Glue ResolveChoice built-in transform to select the most recent value of the column.
Correct Answer: B
Reference: https://towardsdatascience.com/update-and-insert-upsert-data-from-aws-glue-698ac582e562
QUESTION 2
A company has developed an Apache Hive script to batch process data stared in Amazon S3. The script needs to run once every day and store the output in Amazon S3. The company tested the script, and it completes within 30 minutes on a small local three-node cluster.
Which solution is the MOST cost-effective for scheduling and executing the script?
A. Create an AWS Lambda function to spin up an Amazon EMR cluster with a Hive execution step. Set
KeepJobFlowAliveWhenNoSteps to false and disable the termination protection flag. Use Amazon CloudWatch Events to schedule the Lambda function to run daily.
B. Use the AWS Management Console to spin up an Amazon EMR cluster with Python Hue. Hive, and Apache Oozie. Set the termination protection flag to true and use Spot Instances for the core nodes of the cluster. Configure an Oozie workflow in the cluster to invoke the Hive script daily.
C. Create an AWS Glue job with the Hive script to perform the batch operation. Configure the job to run once a day using a time-based schedule.
D. Use AWS Lambda layers and load the Hive runtime to AWS Lambda and copy the Hive script. Schedule the Lambda function to run daily by creating a workflow using AWS Step Functions.
Correct Answer: C
QUESTION 3
An online retail company with millions of users around the globe wants to improve its ecommerce analytics capabilities. Currently, clickstream data is uploaded directly to Amazon S3 as compressed files. Several times each day, an application running on Amazon EC2 processes the data and makes search options and reports available for visualization by editors and marketers. The company wants to make website clicks and aggregated data available to editors and marketers in minutes to enable them to connect with users more effectively.
Which options will help meet these requirements in the MOST efficient way? (Choose two.)
A. Use Amazon Kinesis Data Firehose to upload compressed and batched clickstream records to Amazon Elasticsearch Service.
B. Upload clickstream records to Amazon S3 as compressed files. Then use AWS Lambda to send data to Amazon Elasticsearch Service from Amazon S3.
C. Use Amazon Elasticsearch Service deployed on Amazon EC2 to aggregate, filter, and process the data. Refresh
content performance dashboards in near-real time.
D. Use Kibana to aggregate, filter, and visualize the data stored in Amazon Elasticsearch Service. Refresh content
performance dashboards in near-real time.
E. Upload clickstream records from Amazon S3 to Amazon Kinesis Data Streams and use a Kinesis Data Streams
consumer to send records to Amazon Elasticsearch Service.
Correct Answer: CE
QUESTION 4
A company owns facilities with IoT devices installed across the world. The company is using Amazon Kinesis Data Streams to stream data from the devices to Amazon S3. The company\\’s operations team wants to get insights from the IoT data to monitor data quality at ingestion. The insights need to be derived in near-real time, and the output must be logged to Amazon DynamoDB for further analysis.
Which solution meets these requirements?
A. Connect Amazon Kinesis Data Analytics to analyze the stream data. Save the output to DynamoDB by using the default output from Kinesis Data Analytics.
B. Connect Amazon Kinesis Data Analytics to analyze the stream data. Save the output to DynamoDB by using an AWS Lambda function.
C. Connect Amazon Kinesis Data Firehose to analyze the stream data by using an AWS Lambda function. Save the output to DynamoDB by using the default output from Kinesis Data Firehose.
D. Connect Amazon Kinesis Data Firehose to analyze the stream data by using an AWS Lambda function. Save the data to Amazon S3. Then run an AWS Glue job on schedule to ingest the data into DynamoDB.
Correct Answer: C
QUESTION 5
A data analyst is using AWS Glue to organize, cleanse, validate, and format a 200 GB dataset. The data analyst
triggered the job to run with the Standard worker type. After 3 hours, the AWS Glue job status is still RUNNING. Logs from the job run show no error codes. The data analyst wants to improve the job execution time without
overprovisioning.
Which actions should the data analyst take?
A. Enable job bookmarks in AWS Glue to estimate the number of data processing units (DPUs). Based on the profiled metrics, increase the value of the executor-cores job parameter.
B. Enable job metrics in AWS Glue to estimate the number of data processing units (DPUs). Based on the profiled
metrics, increase the value of the maximum capacity job parameter.
C. Enable job metrics in AWS Glue to estimate the number of data processing units (DPUs). Based on the profiled
metrics, increase the value of the spark.yarn.executor.memoryOverhead job parameter.
D. Enable job bookmarks in AWS Glue to estimate the number of data processing units (DPUs). Based on the profiled metrics, increase the value of the num-executors job parameter.
Correct Answer: B
Reference: https://docs.aws.amazon.com/glue/latest/dg/monitor-debug-capacity.html
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/1MQSgws_qniY9TQnR0aBDnm7qsnIK5-2H/view?usp=sharing
Advanced Amazon DAS-C01 Dumps
geekcert DAS-C01 dumps: https://www.geekcert.com/das-c01.html (Total Questions: 130 Q&A)
DBS-C01 – AWS Certified Database – Specialty
QUESTION 1
A database specialist needs to review and optimize an Amazon DynamoDB table that is experiencing performance issues. A thorough investigation by the database specialist reveals that the partition key is causing hot partitions, so a new partition key is created. The database specialist must effectively apply this new partition key to all existing and new data.
How can this solution be implemented?
A. Use Amazon EMR to export the data from the current DynamoDB table to Amazon S3. Then use Amazon EMR again to import the data from Amazon S3 into a new DynamoDB table with the new partition key.
B. Use AWS DMS to copy the data from the current DynamoDB table to Amazon S3. Then import the DynamoDB table to create a new DynamoDB table with the new partition key.
C. Use the AWS CLI to update the DynamoDB table and modify the partition key.
D. Use the AWS CLI to back up the DynamoDB table. Then use the restore-table-from-backup command and modify the partition key.
Correct Answer: D
QUESTION 2
A large retail company recently migrated its three-tier ecommerce applications to AWS. The company\\’s backend
database is hosted on Amazon Aurora PostgreSQL. During peak times, users complain about longer page load times. A database specialist reviewed Amazon RDS Performance Insights and found a spike in IO:XactSync wait events. The SQL attached to the wait events are all single INSERT statements.
How should this issue be resolved?
A. Modify the application to commit transactions in batches
B. Add a new Aurora Replica to the Aurora DB cluster.
C. Add an Amazon ElastiCache for Redis cluster and change the application to write through.
D. Change the Aurora DB cluster storage to Provisioned IOPS (PIOPS).
Correct Answer: B
QUESTION 3
A Database Specialist needs to define a database migration strategy to migrate an on-premises Oracle
database to an Amazon Aurora MySQL DB cluster. The company requires near-zero downtime for the data migration. The solution must also be cost-effective.
Which approach should the Database Specialist take?
A. Dump all the tables from the Oracle database into an Amazon S3 bucket using datapump (expdp). Run data
transformations in AWS Glue. Load the data from the S3 bucket to the Aurora DB cluster.
B. Order an AWS Snowball appliance and copy the Oracle backup to the Snowball appliance. Once the Snowball data is delivered to Amazon S3, create a new Aurora DB cluster. Enable the S3 integration to migrate the data directly from Amazon S3 to Amazon RDS.
C. Use the AWS Schema Conversion Tool (AWS SCT) to help rewrite database objects to MySQL during the schema migration. Use AWS DMS to perform the full load and change data capture (CDC) tasks.
D. Use AWS Server Migration Service (AWS SMS) to import the Oracle virtual machine image as an Amazon EC2
instance. Use the Oracle Logical Dump utility to migrate the Oracle data from Amazon EC2 to an Aurora DB cluster.
Correct Answer: D
QUESTION 4
A company is looking to move an on-premises IBM Db2 database running AIX on an IBM POWER7
server. Due to escalating support and maintenance costs, the company is exploring the option of moving
the workload to an Amazon Aurora PostgreSQL DB cluster.
What is the quickest way for the company to gather data on the migration compatibility?
A. Perform a logical dump from the Db2 database and restore it to an Aurora DB cluster. Identify the gaps and
compatibility of the objects migrated by comparing row counts from source and target tables.
B. Run AWS DMS from the Db2 database to an Aurora DB cluster. Identify the gaps and compatibility of the objects migrated by comparing the row counts from source and target tables.
C. Run native PostgreSQL logical replication from the Db2 database to an Aurora DB cluster to evaluate the migration compatibility.
D. Run the AWS Schema Conversion Tool (AWS SCT) from the Db2 database to an Aurora DB cluster. Create a
migration assessment report to evaluate the migration compatibility.
Correct Answer: D
Reference: https://docs.aws.amazon.com/SchemaConversionTool/latest/userguide/Schema-ConversionTool.pdf
QUESTION 5
An ecommerce company has tasked a Database Specialist with creating a reporting dashboard that visualizes critical business metrics that will be pulled from the core production database running on Amazon Aurora. Data that is read by the dashboard should be available within 100 milliseconds of an update. The Database Specialist needs to review the current configuration of the Aurora DB cluster and develop a cost-effective solution. The solution needs to accommodate the unpredictable read workload from the reporting dashboard without any impact on the write availability and performance of the DB cluster. Which solution meets these requirements?
A. Turn on the serverless option in the DB cluster so it can automatically scale based on demand.
B. Provision a clone of the existing DB cluster for the new Application team.
C. Create a separate DB cluster for the new workload, refresh from the source DB cluster, and set up ongoing
replication using AWS DMS change data capture (CDC).
D. Add an automatic scaling policy to the DB cluster to add Aurora Replicas to the cluster based on CPU consumption.
Correct Answer: A
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/17np-0I6VFf_tzl7NBZtOe3jlolG74hq6/view?usp=sharing
Advanced Amazon DBS-C01 Dumps
geekcert DBS-C01 dumps: https://www.geekcert.com/aws-certified-database-specialty.html (Total Questions: 185 Q&A)
MLS-C01 – AWS Certified Machine Learning – Specialty
QUESTION 1
A Machine Learning team uses Amazon SageMaker to train an Apache MXNet handwritten digit classifier model using a research dataset. The team wants to receive a notification when the model is overfitting. Auditors want to view the Amazon SageMaker log activity report to ensure there are no unauthorized API calls.
What should the Machine Learning team do to address the requirements with the least amount of code and fewest steps?
A. Implement an AWS Lambda function to long Amazon SageMaker API calls to Amazon S3. Add code to push a
custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
B. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Add code to push a custom metric to
Amazon CloudWatch. Create an alarm in CloudWatch with Amazon SNS to receive a notification when the model is overfitting.
C. Implement an AWS Lambda function to log Amazon SageMaker API calls to AWS CloudTrail. Add code to push a custom metric to Amazon CloudWatch. Create an alarm in CloudWatch with Amazon
SNS to receive a notification when the model is overfitting.
D. Use AWS CloudTrail to log Amazon SageMaker API calls to Amazon S3. Set up Amazon SNS to receive a
notification when the model is overfitting.
Correct Answer: C
QUESTION 2
A manufacturing company asks its Machine Learning Specialist to develop a model that classifies defective parts into one of eight defect types. The company has provided roughly 100000 images per defect type for training During the injial training of the image classification model the Specialist notices that the validation accuracy is 80%, while the training accuracy is 90% It is known that human-level performance for this type of image classification is around 90%
What should the Specialist consider to fix this issue1?
A. A longer training time
B. Making the network larger
C. Using a different optimizer
D. Using some form of regularization
Correct Answer: D
QUESTION 3
IT leadership wants Jo transition a company\\’s existing machine learning data storage environment to AWS as a
temporary ad hoc solution The company currently uses a custom software process that heavily leverages SOL as a query language and exclusively stores generated csv documents for machine learning
The ideal state for the company would be a solution that allows it to continue to use the current workforce of SQL
experts The solution must also support the storage of csv and JSON files, and be able to query over semi-structured data The following are high priorities for the company:
1.
Solution simplicity
2.
Fast development time
3.
Low cost
4.
High flexibility
What technologies meet the company\\’s requirements?
A. Amazon S3 and Amazon Athena
B. Amazon Redshift and AWS Glue
C. Amazon DynamoDB and DynamoDB Accelerator (DAX)
D. Amazon RDS and Amazon ES
Correct Answer: B
QUESTION 4
A technology startup is using complex deep neural networks and GPU compute to recommend the company\\’s
products to its existing customers based upon each customer\\’s habits and interactions. The solution currently pulls each dataset from an Amazon S3 bucket before loading the data into a TensorFlow model pulled from the company\\’s Git repository that runs locally. This job then runs for several hours while continually outputting its progress to the same S3 bucket. The job can be paused, restarted, and continued at any time in the event of a failure, and is run from a central queue.
Senior managers are concerned about the complexity of the solution\\’s resource management and the costs involved in repeating the process regularly. They ask for the workload to the automated so it runs once a week, starting Monday and completing by the close of business Friday.
Which architecture should be used to scale the solution at the lowest cost?
A. Implement the solution using AWS Deep Learning Containers and run the container as a job using AWS Batch on a GPU-compatible Spot Instance
B. Implement the solution using a low-cost GPU compatible Amazon EC2 instance and use the AWS Instance
Scheduler to schedule the task
C. Implement the solution using AWS Deep Learning Containers, run the workload using AWS Fargate running on Spot Instances, and then schedule the task using the built-in task scheduler
D. Implement the solution using Amazon ECS running on Spot Instances and schedule the task using the ECS service scheduler.
Correct Answer: C
QUESTION 5
A data scientist uses an Amazon SageMaker notebook instance to conduct data exploration and analysis. This requires certain Python packages that are not natively available on Amazon SageMaker to be installed on the notebook instance.
How can a machine learning specialist ensure that required packages are automatically available on the notebook
instance for the data scientist to use?
A. Install AWS Systems Manager Agent on the underlying Amazon EC2 instance and use Systems Manager
Automation to execute the package installation commands.
B. Create a Jupyter notebook file (.ipynb) with cells containing the package installation commands to execute and place the file under the /etc/init directory of each Amazon SageMaker notebook instance.
C. Use the conda package manager from within the Jupyter notebook console to apply the necessary conda packages to the default kernel of the notebook.
D. Create an Amazon SageMaker lifecycle configuration with package installation commands and assign the lifecycle configuration to the notebook instance.
Correct Answer: B
Reference: https://towardsdatascience.com/automating-aws-sagemaker-notebooks-2dec62bc2c84
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/1GfXZFcmQAhcWMgi2b1wgrH76R1MynSlh/view?usp=sharing
Advanced Amazon MLS-C01 Dumps
geekcert MLS-C01 dumps: https://www.geekcert.com/aws-certified-machine-learning-specialty.html (Total Questions: 210 Q&A)
SCS-C01 – AWS Certified Security – Specialty
QUESTION 1
Your company has defined a set of S3 buckets in AWS. They need to monitor the S3 buckets and know the source IP address and the person who make requests to the S3 bucket. How can this be achieved?
Please select:
A. Enable VPC flow logs to know the source IP addresses
B. Monitor the S3 API calls by using Cloudtrail logging
C. Monitor the S3 API calls by using Cloudwatch logging
D. Enable AWS Inspector for the S3 bucket
Correct Answer: B
The AWS Documentation mentions the following Amazon S3 is integrated with AWS CloudTrail. CloudTrail is a service that captures specific API calls made to Amazon S3 from your AWS account and delivers the log files to an Amazon S3 bucket that you specify. It captures API calls made from the Amazon S3 console or from the Amazon S3 API. Using the information collected by CloudTrail, you can determine what request was made to Amazon S3, the source IP address from which the request was made, who made the request when it was made, and so on Options A,C and D are invalid because these services cannot be used to get the source IP address of the calls to S3 buckets For more information on Cloudtrail logging, please refer to the below Link: https://docs.aws.amazon.com/AmazonS3/latest/dev/cloudtrail-logeins.html The correct answer is: Monitor the S3 API calls by using Cloudtrail logging
QUESTION 2
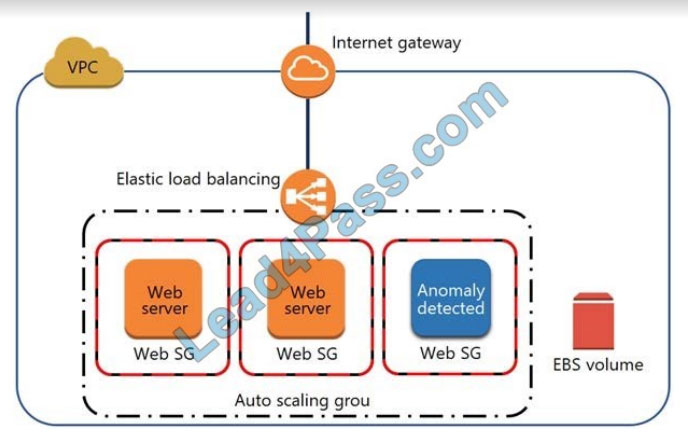
A security engineer noticed an anomaly within a company EC2 instance as shown in the image. The engineer must now investigate what is causing the anomaly.
What are the MOST effective steps to take to ensure that the instance is not further manipulated, while allowing the engineer to understand what happened?
A. Remove the instance from the Auto Scaling group. Place the instance within an isolation security group, detach the EBS volume, launch an EC2 instance with a forensic toolkit, and attach the EBS volume to investigate.
B. Remove the instance from the Auto Scaling group and the Elastic Load Balancer. Place the instance within an
isolation security group, launch an EC2 instance with a forensic toolkit, and allow the forensic toolkit image to connect to the suspicious instance to perform the investigation.
C. Remove the instance from the Auto Scaling group. Place the instance within an isolation security group, launch an EC2 instance with a forensic toolkit, and use the forensic toolkit image to deploy an ENI as a network span port to inspect all traffic coming from the suspicious instance.
D. Remove the instance from the Auto Scaling group and the Elastic Load Balancer. Place the instance within an
isolation security group, make a copy of the EBS volume from a new snapshot, launch an EC2 instance with a forensic toolkit, and attach the copy of the EBS volume to investigate.
Correct Answer: D
QUESTION 3
A Devops team is currently looking at the security aspect of their CI/CD pipeline. They are making use of AWS
resource? for their infrastructure. They want to ensure that the EC2 Instances don\\’t have any high security
vulnerabilities. They want to ensure a complete DevSecOps process. How can this be achieved?
Please select:
A. Use AWS Config to check the state of the EC2 instance for any sort of security issues.
B. Use AWS Inspector API\\’s in the pipeline for the EC2 Instances
C. Use AWS Trusted Advisor API\\’s in the pipeline for the EC2 Instances
D. Use AWS Security Groups to ensure no vulnerabilities are present
Correct Answer: B
Amazon Inspector offers a programmatic way to find security defects or misconfigurations in your operating systems and applications. Because you can use API calls to access both the processing of assessments and the results of your assessments, integration of the findings into workflow and notification systems is simple. DevOps teams can integrate Amazon Inspector into their CI/CD pipelines and use it to identify any pre- existing issues or when new issues are introduced. Option A.C and D are all incorrect since these services cannot check for Security Vulnerabilities. These can
only be checked by the AWS Inspector service. For more information on AWS Security best practices, please refer to below URL: https://d1.awsstatic.com/whitepapers/Security/AWS Security Best Practices.pdl The correct answer is: Use AWS Inspector API\\’s in the pipeline for the EC2 Instances
QUESTION 4
A Security Engineer accidentally deleted the imported key material in an AWS KMS CMK.
What should the Security Engineer do to restore the deleted key material?
A. Create a new CMK. Download a new wrapping key and a new import token to import the original key material
B. Create a new CMK Use the original wrapping key and import token to import the original key material.
C. Download a new wrapping key and a new import token Import the original key material into the existing CMK.
D. Use the original wrapping key and import token Import the original key material into the existing CMK
Correct Answer: B
Reference: https://docs.aws.amazon.com/kms/latest/developerguide/importing-keys.html
QUESTION 5
Your company has created a set of keys using the AWS KMS service. They need to ensure that each key is only used for certain services. For example , they want one key to be used only for the S3 service. How can this be achieved? Please select:
A. Create an IAM policy that allows the key to be accessed by only the S3 service.
B. Create a bucket policy that allows the key to be accessed by only the S3 service.
C. Use the kms:ViaService condition in the Key policy
D. Define an IAM user, allocate the key and then assign the permissions to the required service
Correct Answer: C
Option A and B are invalid because mapping keys to services cannot be done via either the IAM or bucket policy Option D is invalid because keys for IAM users cannot be assigned to services This is mentioned in the AWS Documentation The kms:ViaService condition key limits use of a customer-managed CMK to requests from particular AWS services. (AWS managed CMKs in your account, such as aws/s3, are always restricted to the AWS service that created them.)
For example, you can use kms:V1aService to allow a user to use a customer managed CMK only for requests that
Amazon S3 makes on their behalf. Or you can use it to deny the user permission to a CMK when a request on their
behalf comes from AWS Lambda. For more information on key policy\\’s for KMS please visit the following URL:
https://docs.aws.amazon.com/kms/latest/developereuide/policy-conditions.html The correct answer is: Use the
kms:ViaServtce condition in the Key policy
Get (Q1-Q13) Exam PDF
Google Drive: https://drive.google.com/file/d/1SRcVc10jCSyHQITRuTpL-oDTfw6mE6jp/view?usp=sharing
Advanced Amazon SCS-C01 Dumps
geekcert SCS-C01 dumps: https://www.geekcert.com/aws-certified-security-specialty.html (Total Questions: 550 Q&A)
The above shared Amazon AWS Certified Specialty free practice questions and free exam PDFs for the entire series of Amazon AWS Certified Specialty, as well as advanced exam dumps. You can practice the test online, and you can download the PDF for learning. You can also get advanced exam dumps to help you pass the exam easily.
PS. More Amazon exam content can enter the Awsexamdumps channel


